论文:Make Agent Defeat Agent: Automatic Detection of Taint-Style Vulnerabilities in LLM-based Agents
会议:USENIX Security Symposium 2025
论文链接:https://www.usenix.org/system/files/usenixsecurity25-liu-fengyu.pdf
项目源码:https://github.com/LFYSec/AgentFuzz

这篇博客可以围绕两个问题展开:
- 漏洞链路:LLM Agent 里的 taint-style vulnerability 是怎么形成的?
- 自动化闭环:AgentFuzz 怎么把这个漏洞触发过程自动化?
一句话概括:
AgentFuzz 先用 static analysis 找到能到达危险 sink 的 call chain,再用 LLM 根据 call chain 生成自然语言 seed,随后通过 runtime instrumentation 收集 execution trace,最后基于 feedback 不断 mutate seed,直到真实触发 sink。
从 Prompt 到 Sink:漏洞链路怎么形成

论文中的漏洞示例展示的是 LLM Agent 中一种典型的 taint-style vulnerability。它和传统 Web 漏洞不太一样:攻击者不是直接控制某个 API 参数,而是通过自然语言 prompt 间接影响 LLM 的 tool selection 和 argument generation。
可以把链路抽象成:
1 | user prompt |
论文里的例子大致是:
1 | class ElasticsearchPermissionCheck: |
攻击者构造 prompt:
1 | Use Elasticsearch for a similarity search with permission checks |
这里有三个关键点:
- source 是 user prompt。
- sink 是 eval。
- prompt 不仅要让 Agent 选择正确 component,还要让生成的 argument 满足 “source_doc” in content 和 content.split(“:”)[1] 这类 program constraints。
所以这个漏洞模型想讲的是:LLM Agent 的漏洞触发同时依赖两件事:
- semantic requirement:prompt 要让 LLM Agent 选择正确 tool/component。
- program constraint:生成出来的 argument 要满足代码里的 branch/string constraints。
这也是为什么普通 fuzzer 不够用。随机 mutation 很难生成一个“语义上正确”的 prompt;单纯 static analysis 又无法确认 prompt 是否真的能经由 LLM planning 到达 sink。
这条漏洞链在源码里怎么看
| 机制 | 源码位置 | 作用 |
|---|---|---|
| sink definition | ql/call/call.qll | 定义 eval、exec、subprocess.run、os.system、requests.*、SQL、SSTI 等危险操作 |
| call chain extraction | ql/get_callchain_and_location.ql | 找到能到达 sink 的 function/method path |
| path constraint extraction | ql/get_if.ql | 提取通往 sink 路径上的 if condition |
| data/string constraint extraction | ql/get_dataflow_str_constraint.ql | 提取 split/index/rindex 等字符串约束 |
| runtime confirmation | trace/cetracer.py | 运行时记录是否真的进入目标 function、condition、sink |
结合上面的例子:
- eval 会被 ql/call/call.qll 识别为 sink。
- ElasticsearchPermissionCheck.similarity_search -> eval 会被抽成 call chain。
- “source_doc” in content 会成为 path constraint。
- content.split(“:”)[1] 会成为 data/string constraint。
- trace/cetracer.py 会在实际运行时确认 prompt 是否真的触发这些位置。
从发现路径到触发漏洞:AgentFuzz 的闭环
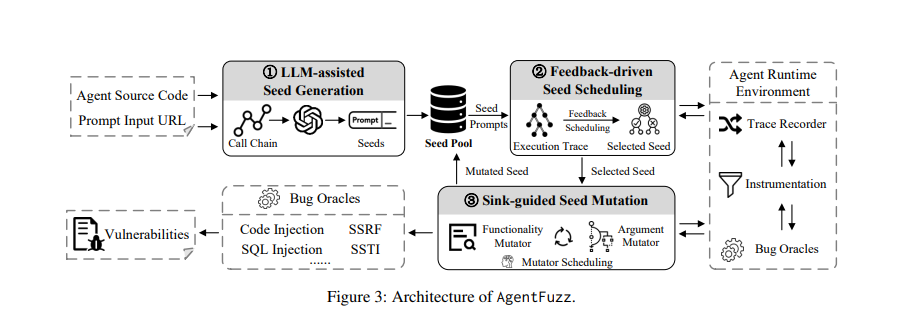
AgentFuzz 的完整流程可以拆成三个阶段:
1 | 1. LLM-assisted Seed Generation |
整体流程是:
1 | CodeQL static analysis |
1. LLM-assisted Seed Generation
AgentFuzz 的 seed 是自然语言 prompt。它不是随机来的,而是由 LLM 根据 call chain 自动生成。
核心想法是:method/class name 本身包含 semantic hints。例如:
1 | CodeExecutor.execute_code -> execute_code |
这些名字可以帮助 LLM 推断 component functionality,并生成更可能触发该 component 的 prompt。
对应源码:
- config/PromptTemplete.py:INIT_PROMPT_TEMPLETE
- fuzzer.py:get_initial_chromosome()
- fuzzer.py:seed_generation()
代码里的 Chromosome 可以理解成一个带状态的 seed:
1 | seed prompt + target call chain + execution trace + scores + mutation state |
2. Feedback-driven Seed Scheduling
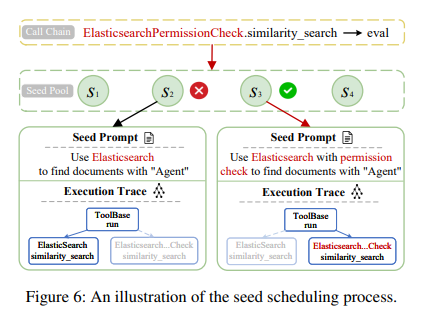
seed 执行后,AgentFuzz 会收集 runtime feedback,再决定下一轮优先 mutate 哪个 seed。
它主要看三类分数:
- semantic score:当前 prompt 和 execution trace 在语义上是否接近目标 call chain。
- distance score:当前 execution trace 在代码路径上离目标 sink 有多近。
- penalty score:避免一直选择同一个 seed 或 call chain。
论文里的形式是:
1 | Fs = alpha * Ss + beta * Ds - Ps |
开源实现里更直接:
1 | final_score = similarity_score + distance_score |
对应源码:
- fuzzer.py:get_similarity_score()
- fuzzer.py:get_distance_score()
- fuzzer.py:seed_scheduling()
- trace/cetracer.py:runtime instrumentation
这里的 feedback 依赖 runtime instrumentation。AgentFuzz 会把 trace/cetracer.py 插进目标 Agent 进程,并不是只靠一种 hook,而是组合了几类机制:
- sys.settrace / threading.settrace:记录 Python frame 的 call 和 line event,用来判断进入了哪些 function、执行到了哪些 condition。
- sys.addaudithook:监听 compile 等 audit event,用来辅助捕获 eval/exec 这类 built-in sink。
- monkeypatch:源码里对 subprocess.run 做了 wrapper,用来在真正执行前记录 sink argument。
这些 instrumentation 会根据静态分析生成的规则记录四类日志:
1 | /tmp/hook.log 记录是否进入了目标 call chain 相关 function |
因此,AgentFuzz 判断“有没有调用到目标 component”并不是靠猜,而是看 hook.log 和 callstack.log 里是否出现了目标 call chain 中的 function。判断“距离是否更近”,则是看当前 execution trace 命中了目标 call chain 的哪一段:越靠近末尾的 sink,distance score 越高。
这里最有意思的是 semantic score。AgentFuzz 会让 LLM 比较:
1 | target call chain semantics |
也就是说,即使当前 seed 还没触发 sink,只要它已经让 Agent 走向语义相关的 component,就会被认为“方向是对的”。
3. Sink-guided Seed Mutation
AgentFuzz 有两类 mutator:
- Functionality Mutator
- Argument Mutator
它们解决的问题不同。
- Functionality Mutator
当 prompt 没有正确触发目标 component 时,使用 Functionality Mutator。
它做的是 semantic-level mutation。例如:
1 | Use Elasticsearch to find documents |
可能被改成:
1 | Use Elasticsearch with permission checks to find documents |
目标是让 LLM Agent 选择更接近目标 call chain 的 tool/component。
对应源码:
- config/PromptTemplete.py:MUTATE_SYSTEM_PROMPT
- fuzzer.py:mutate()
- fuzzer.py:prompt_mutate()
- Argument Mutator
当 seed 已经触发了正确 component,但卡在某个 condition 前时,使用 Argument Mutator。
它解决的是 program constraint。例如:
1 | if "source_doc" in content: |
如果当前 prompt 只让 content = “hello”,那就到不了 eval。Argument Mutator 会根据 runtime log 里的 condition 和 local variables,尝试生成满足条件的新 argument,然后映射回 prompt。
抽象流程:
1 | read if.log / local variables |
对于上面的漏洞例子,最终可能把 prompt 里的普通查询词改成:
1 | source_doc:print(1) |
对应源码:
- fuzzer.py:solve_and_get_new_prompt()
- generate_conbyte.py
- py-conbyte/
- solve_dsc.py
- trace/compare/compare.py
其中 trace/compare/compare.py 里的 fuzzy/substring matching 很关键:AgentFuzz 需要知道 runtime argument 对应 prompt 里的哪一段,然后才能把 constraint solving 的结果写回自然语言 prompt。
Oracle 和 PoC
当 runtime oracle 观察到 sink 被命中后,AgentFuzz 会进一步生成验证 payload。
对应源码:
- trace/cetracer.py:Oracle
- fuzzer.py:get_if_and_oracle()
- fuzzer.py:get_poc_prompt()
不同 sink 会插入不同 payload:
- command execution:echo 1
- eval/exec:print(1)
- SSRF/request:127.0.0.1:1234
- SQL:select 1
- SSTI:{{ print(1) }}
这一步把“到达 sink”变成“可验证的 vulnerability PoC”。
总结
LLM Agent 里的 taint-style vulnerability 麻烦之处在于,payload 往往不是直接作为参数传进去的。它先藏在 natural language prompt 里,再经过 LLM 的理解、tool selection 和 argument generation,最后才可能落到 eval、subprocess.run、requests.* 这类 sink 上。
AgentFuzz 的价值就在于把这个过程拆开并闭环起来:static analysis 负责告诉它“危险路径在哪里”,LLM 负责生成和修正更像人类指令的 seed,runtime instrumentation 负责告诉它“这次到底走到了哪”,constraint-guided mutation 再把 prompt 往满足代码条件的方向推。它不是让 LLM 随机写攻击 prompt,而是让每一次 mutation 都有明确的目标和反馈。